Hi. I have to import from SVN to Git some small part (several subfolders) of huge monorepository with long history.
History of development was - first year these folders are being developed in trunk then dedicated branch was created, and development was being continued to there for next 2 years till now.
I have no problems to import branch separately, using directory layout. But when I trying to configure import trunk + my_branch then SubGit freezes trying to get even 1st revision since specified start point in its config.
I waited for several hours without any success. Then I ran Fiddler (proxy server with ability to view packets), and sent SVN traffic via there. And then I discovered, that SubGit wants to obtain “update report” for whole huge repository (without any exclude folders preferences), and it seems that it is quite impossible to get - response contains binary data and lot of XML information per each file, and this simple response can have size of tens of gigabytes. (I was not able to ever wait for its finish to determine whole size, so there is an intermediate results).
Is there any possibilities to get SVN update report for specific folders, or get it part by part, to get rid of this problem?
Thanks.
Hi Viacheslav,
thank you for reaching out to us on that matter!
I’ve got a couple of questions, though – do I understand correctly that you first tried to import my_branch (and that was successfully) and added trunk on the second attempt? If so, may I ask you if trunk was empty at the very beginning (at r1) or some data was present in the repository from scratch?
Prior to the initial import SubGit indeed reads the repository history, but at this stage no actual data (such as binary or XML information for files) is requested, just actual repository history. After the history analysis and preliminary actions SubGit starts the initial import and at this stage it indeed requests and downloads the whole revisions data. As far as I understand, you tried to exclude some of the folders using excludePath configuration options, correct? Despite of its name this feature does not exclude the paths at the initial data load stage, for the data integrity sake the complete revision data is downloaded to SubGit machine and the setting is being applied only after that to the downloaded data, that’s why you’re seeing all that data is being transferred.
We have an experimental feature that allows to not to download the complete revision data applying the exclusion on the SVN server side. I’d like to emphasize, though, that this is experimental feature that is not guaranteed to work correctly for any SVN repository. It can be set like follows:
[svn]
…
optimizeExcludePath = true
It should be set prior to the initial import; besides, the excludePath patterns must be set explicitly without wildcards, otherwise the setting is not applied and the setting will be applied on SubGit side.
Hope this will help.
Thank you for your answer.
do I understand correctly that you first tried to import my_branch (and that was successfully)
Yes, this is correct. And that was really fast.
and added trunk on the second attempt?
Not exactly. After first sucsefful attempt I created a new clean git repo (keeping first repo aside as “plan B result”) and started import from scratch with it.
We have an experimental feature that allows to not to download the complete revision data applying the exclusion on the SVN server side.
Thank you, I will check it today and let know, if I succeed!
UPDATE: I tried the advanced option. Unfortunately, nothing has been changed. By the way, I could not find this option via plain binary search through all files in my SubGit 3.3.11 binaries - is this advanced option present in that build?
I managed to start SVN fetch process in SubGit via increasing the number of minimal revision in config to +50. Why such strange action did the trick?- who knows… I suppose it could be storage-related issue.
This is not finished yet, but for me there is some confidence in success now.
Thank you for your help!
Hi Viacheslav,
glad to hear the migration works now.
The option is definitely present in this build; actually, it’s been introduced some time ago it is present even in the previous SubGit release. But as I mentioned before, it’s just an experimental feature that has not been tested properly and apparently it just does not work for your repository :(
However, the minimalRevision is another valid workaround for the issue: SubGit starts the initial import from the revision set by this option and thus may omit some of erroneous revisions if there are any. In this case, the revision 50 probably contains less data comparing to the revision 1 and that is what did the trick, I assume.
The successful start of the import gave me the opportunity to learn a little more about my problem. It turns out that SubGit only requests a full SVN report for revisions where the so-called “revision properties” have been changed at the global level (just properties, no file changes). For other revisions, SubGit specifies the “trunk” subdirectory in the request to svn server, and such request runs very quickly.
It is these revisions that slow down the whole process. If I skip them every time by changing the numbers in the “.metadata” file, then the rest of the revisions (containing the useful changes) are imported very quickly.
I managed to localize the problem - in my repository there are a large number of commits containing just a change in the revision property. But is there any way to skip them? Now manual processing + restarting takes 95% of the time.
Thanks!
It looks like I found old similar issue, unfortunately, without solution.
https://issues.tmatesoft.com/issue/SGT-1247
Hi Viacheslav,
that issue had not been resolved as didn’t get a chance to investigate it deeper and at the same time we hadn’t managed to reproduce the issue in our own environment. Apparently this is something specific for a particular SVN repository, but unfortunately not clear what exactly. An assumption that comes to my mind is that the svn:eol-style is the property that’s being changed in those revisions and in such a case the low import performance is expected as the eols translation is slow. For that case it may help disabling the eols translation:
[translate]
eols = false
As for the workaround – I’m afraid SubGit has no functionality to skip intermediate revisions, and moreover, I’d like to encourage you to not use such an approach, especially if you are about to use mirror as it definitely will lead to a broken mirror and even in case of a one-time import it may lead to fatal error during the import. It would probably be better either to import the repository not from the first revision, but from a revision near to the latest one – this can be done with the minimalRevision setting – or to switch off the properties translation like this:
[translate]
ignores = false
eols = false
otherProperties = false
and if those revisions only contain properties changes, then it may worth to not to create correspondent Git commits as they will be empty:
[translate]
ignores = false
eols = false
otherProperties = false
createEmptyGitCommits = false
Thank you for answer, Ildar. Actually I have all these options already in my config.
The problem with extremely slow report between specific commits is obviously repository-based. But the road to this problem is that SubGit considers these revisions (with only changes in global revision properties, without any file changes) as they affect whole repository, and that’s why it requests full diff report (from root of repo) instead of partial one (from /trunk only). But in our repository all these revisions don’t affect any files, they contain only custom revision properties.
By some reason, such report takes extremely long time and traffic to obtain from SVN. However there’s no any real file changes between, so, I propose it looks like bug when SVN server tries to return lots of binaries and XML in that report.
It takes about 40-60 minutes to wait for each that report. Therefore, the only thing I invented to deal with that is to break import each time and manually skip all these revisions (incl. visual check if they really do not contain any files). I have done it hundred of times, and a couple of hundreds is waiting ahead.
I don’t think that there is any direct logical error in SubGit here, just wrote that my yesterday’s post to get a minimal chance to gather some workaround, if it already exists. Thank you for your attention.
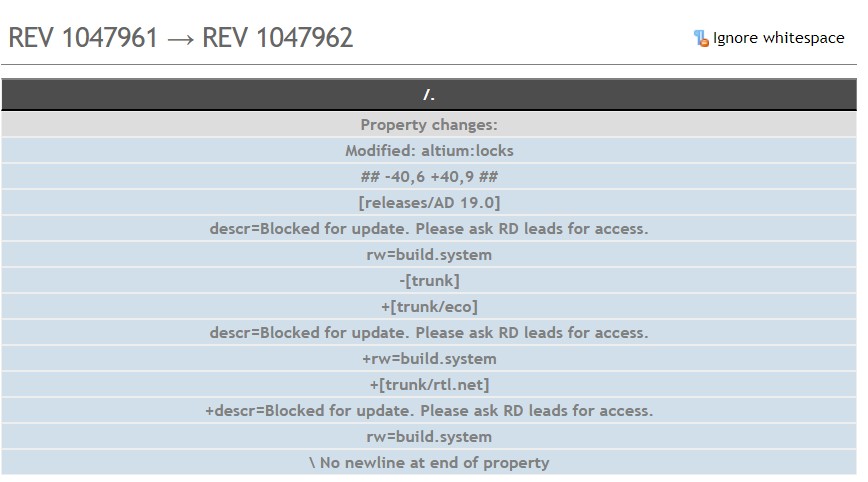
PS: Here is example of such commit which causes stuck:
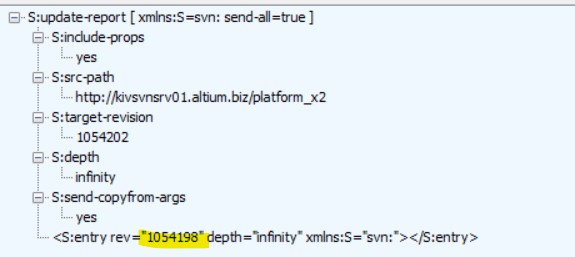
Here is an example of XML trace of report request to SVN server which leads to stuck. Interesting fact - if I replace marked yellow number to 1054202 in that request, server responds as lightning fast, and returns correct result.
I managed to solve my problem, and that was the last interesting fact (last picture on previous post) which helped me to find the solution.
I was investigating the way how to “fix” entry revision number in slow reports, and Fiddler helped me here a lot. It turns out, that it supports processing request/response via script engine. It took some time to write something with Fiddler’s near-zero documented stuff, but finaly I got result which speeded up my conversion dramatically.
static function OnBeforeRequest(oSession: Session) {
if (oSession.HTTPMethodIs("REPORT") && (oSession.url.Contains("myserver.com/my_project/!svn/vcc/default"))) {
oSession.utilDecodeRequest();
var oBody = System.Text.Encoding.UTF8.GetString(oSession.requestBodyBytes);
if (oBody.Contains("S:update-report") && !oBody.Contains("trunk"))
{
var oRegEx1 = /<S:target-revision>(\d+)<\/S:target-revision>/gmi;
var oRevision0 = oBody.match(oRegEx1);
var oRevision = oRevision0.ToString().Replace("<S:target-revision>", "").Replace("</S:target-revision>", "");
var oRegEx = /(<S:entry rev=\")(\d+)(\" depth=\"infinity\"><\/S:entry>)/gmi;
oBody = oBody.replace(oRegEx, "$1" + oRevision + "$3");
oSession.utilSetRequestBody(oBody);
}
}
......
And then I put all my SVN traffic through Fiddler.
I would not advice this hack to anyone who doesn’t realize all consequences. But for me, there was no any other options.
With this hack conversion of my repo took only about 2 hours. Did it twice already (with minor corrections). And last iteration gave me an ideal result.
Thank you for support and for really great and powerful conversion tool!
Hi Vyacheslav,
thank you for letting us know, that’s an interesting solution, indeed!